From Heuristics to Abstractions: Toward Structured Prompt Engineering
How DSPy reframes prompting as a software engineering discipline — and what that means for teams shipping LLM systems in production.
The rise and reality of prompt engineering
When large language models first became widely accessible, a new craft emerged almost overnight: prompt engineering. Natural language phrases — historically the least contributing input in a computing system — suddenly became the primary interface for steering model behavior. New use cases exploded, from chatbots to agents, all powered by these magical strings we call prompts.
The early phase had its usual cycles. This was the shiny new art in town, and successful recipes started circulating. “Use chain-of-thought.” “Add role instructions.” “Be explicit about format.” “Threaten the model in CAPITAL LETTERS.” Software engineering teams suddenly looked more like magazine editorial desks, debating vocabulary and punctuation.
The friction: manual prompting doesn’t scale
Then the proof-of-concept phase ended, and the reality of production set in. As production systems face real world complexity and new model capabilities arrived at a relentless pace, something became clear: prompts are incredibly powerful, yet fundamentally brittle.
- Behavioral Brittleness. Minor word changes break behavior unpredictably. Building reliable systems meant constant tweaking — adjusting wording, adding examples, rephrasing instructions.
- Lack of generalization. A prompt is often tethered to a specific environment; what works for one dataset or one model often fails on another. This forces teams into a cycle of repeated tuning every time a new test set emerges or a more capable model is released.
- Bootstrap vs. Improvement. Getting to a working demo with prompts feels magical. The first 90% of a demo feel effortless, the last mile of production-grade accuracy is grueling. And when the use case shifts or a new model lands, the churn becomes significant.
- Intuition engineering. Improvements rely on manual, intuition-driven tuning because there’s no obvious structural way to optimize a prompt.
This raises an uncomfortable question: how do you scale a team on a skill set like this?
But then prompts are here to stay, which leaves us in an interesting bind. An industry built on precision now has to operate in a medium known for ambiguity and interpretation.
Looking back to move forward
Sometimes pausing to see what worked before genuinely helps, even in a non-deterministic world. DSPy, as a framework, seems to have done exactly that.
Several frameworks have emerged for LLM engineering, mostly targeting application patterns — chaining, RAG, agents, flows. DSPy goes after a different elephant in the room: prompt engineering itself.
DSPy — Declarative Self-improving Python — combines classic programming and machine learning constructs to navigate this messy space. At its core, it breaks prompt construction into components, abstracts them, modularizes LLM behaviors, and uses that structure to train and optimize. The framework often gets reduced to “an automated prompt optimizer,” but what it really offers is a way to treat prompt construction, model behaviors, and LLM programs as composable entities — stitched together like traditional programs, and therefore far more controllable than hand-woven prompts.
How DSPy goes about it
Abstraction
Look closely at a system prompt and you can decompose it into parts: a message to the language model with inputs, task instructions, nudging phrases, examples to learn from, and an expected output format. Already we’re seeing how a prompt can be broken down structurally.
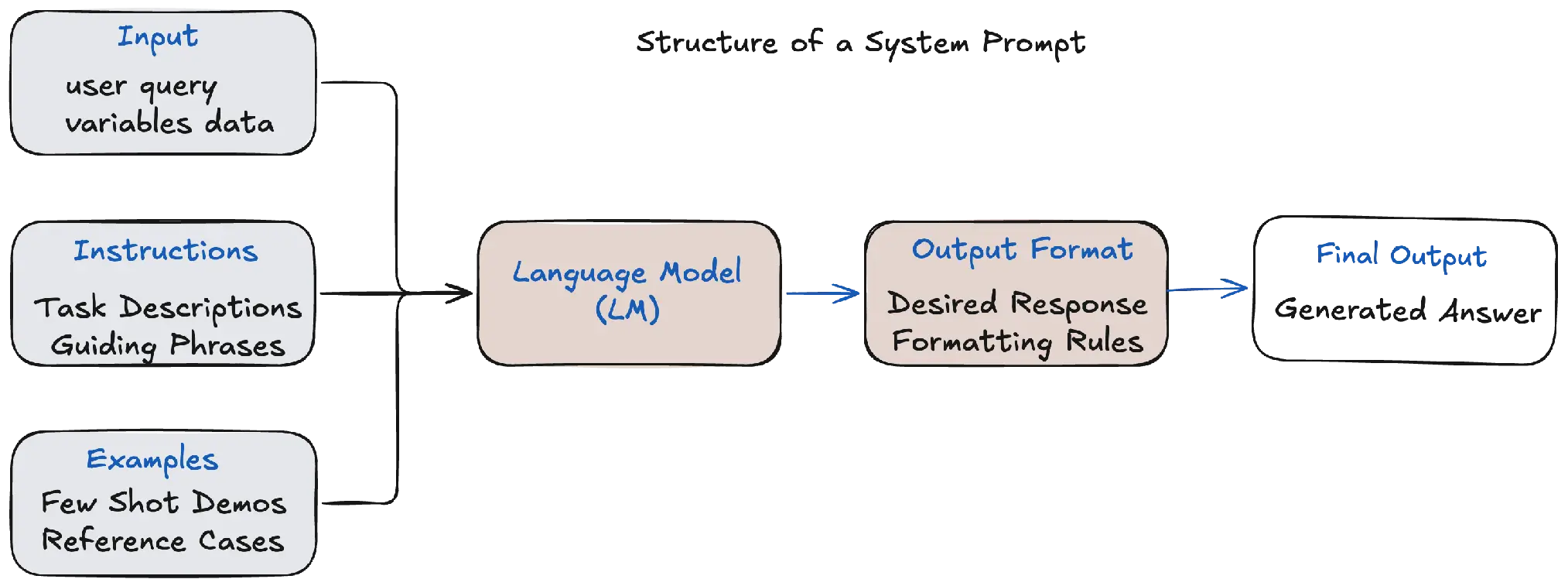
This is exactly how DSPy brings order to the chaos, and the starting point is a Signature. A signature declares the input/output contract for a model call. While the whole point of DSPy is that prompts can be constructed automatically, signatures are where intent is made explicit.
from typing import Literal
import dspy
class SupportCategory(dspy.Signature):
"""Classify the customer's query into the correct support category."""
query: str = dspy.InputField(desc="Customer's message or issue")
category: Literal[
'billing',
'technical_issue',
'account_access',
'refund_request',
'order_issue',
'general_query'
] = dspy.OutputField(desc="Best matching support category")The docstring carries the starter instructions; the input and output fields carry their own descriptions.
Modularization
The next building block is Modules, and this is where things get interesting. Just as prompts can be decomposed structurally, an LLM program can be decomposed into a set of model calls — each with its own prompt, inputs, and outputs — piped together. This modularity allows for dual-layer optimization: refining the local performance of individual calls while simultaneously tuning the program to meet global, system-level objectives.
DSPy modules do three important things.
First, they provide built-in primitives for common LLM behaviors — completion, reasoning, chain-of-thought, and so on:
# create predictor module
classify = dspy.Predict(SupportCategory)
# use it
result = classify(query="I can't log into my account")
print(result.category)Second, this is where DSPy meets PyTorch for LLM engineering. Modules function as layers containing “learnable parameters” that are tuned to maximize performance. Crucially, these parameters are model-agnostic: they can be optimized as high-level prompts or as underlying model weights via fine-tuning.
Internally, each module encapsulates three core elements that the framework optimizes:
Instruction: The declarative task description.
Demos: The few-shot examples that anchor model behavior.
Signature: The structured input/output schema.
By treating these as tunable variables rather than hard-coded strings, DSPy allows to transition seamlessly from prompt optimization on large models to weight-based fine-tuning on smaller, specialized models—all without changing a single line of the program logic.
Third, modules let you compose model calls into a larger program with a overall objective. n a traditional setup, if you classify a customer’s intent and then generate a response based on that category, you are managing two isolated strings. In DSPy, these are piped together as a unified flow and optimized jointly.
class SupportAgent(dspy.Module):
def __init__(self):
super().__init__()
self.classifier = dspy.Predict(SupportCategory)
self.responder = dspy.Predict(ResponseGenerator) # signature defined separately
def forward(self, query):
category = self.classifier(query=query).category
response = self.responder(query=query, category=category)
return responseEvaluation
To optimize parameters, we need Metrics. DSPy supports everything from simple equality checks to program-as-metric setups, where an LLM judges intermediate steps. A metric is just a function that returns a score — and that function can be as simple or as elaborate as the use case demands.
For pure classification, a simple metric works:
def support_metric(example, pred, trace=None):
return pred.category == example.categoryFor the classification-plus-response scenario, we can build a DSPy program that acts as the metric — useful because the metric itself can be inspected or even optimized:
class ResponseQuality(dspy.Signature):
query = dspy.InputField()
category = dspy.InputField()
response = dspy.InputField()
score = dspy.OutputField(desc="Rate the response from 1 to 5 on correctness, relevance, and helpfulness.")
class ResponseMetric(dspy.Module):
def __init__(self):
super().__init__()
self.judge = dspy.Predict(ResponseQuality)
def forward(self, example, pred, trace=None):
result = self.judge(
query=example.query,
category=pred.category,
response=pred.response,
)
return int(result.score) >= 4
metric = ResponseMetric()Optimization
With structure, modules, and metrics in place, the remaining question is how does DSPy actually improve the system?
At a surface level, optimization in DSPy is about tuning the parameters inside each module. DSPy formalizes this through optimizers (originally called teleprompters — you’ll still see the legacy name in import paths like dspy.teleprompt). An optimizer improves a program by refining its parameters against a metric and a dataset.
What gets tuned depends on the optimizer. Broadly, they fall into a few families:
- Few-shot learners that automatically construct and refine demonstrations:
LabeledFewShot,BootstrapFewShot,BootstrapFewShotWithRandomSearch,KNNFewShot. - Instruction optimizers that explore better natural-language instructions per module:
COPRO,MIPROv2,GEPA,SIMBA. - Weight tuners that go a step further and fine-tune model weights:
BootstrapFinetune. - Hybrid approaches that combine strategies:
BetterTogether.
Take BootstrapFewShot as an example. The idea is intuitive — run the program on examples, collect successful execution traces, and use them as few-shot demonstrations for subsequent runs. Over iterations, the system effectively learns better prompting strategies from its own behavior.
Applied to the support agent:
from dspy.teleprompt import BootstrapFewShot
# define optimizer with metric
optimizer = BootstrapFewShot(metric=ResponseMetric())
# compile (optimize) the program
compiled_agent = optimizer.compile(
SupportAgent(),
trainset=train_data,
)
# use optimized program
response = compiled_agent(query="I was charged twice for my order")
print(response)The important point isn’t just that the prompts improve — it’s that the entire program is optimized as a unit. The classifier and responder are no longer tuned in isolation; their interaction is evaluated and refined against the final outcome.
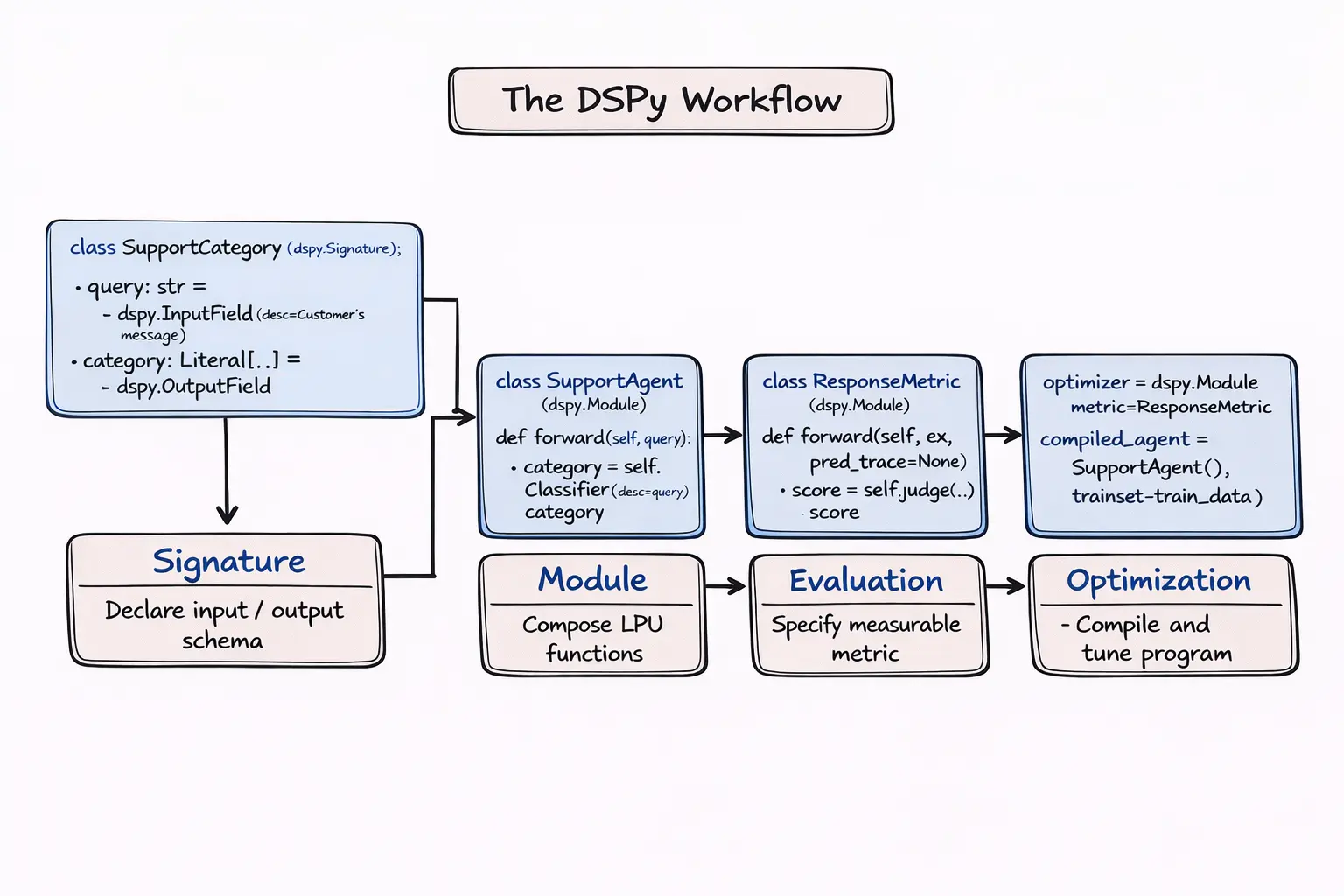
Where DSPy makes it work
DSPy tends to get reduced to its headline feature — optimizers — but the real value is in its systemic approach. This gets reflected in
Building blocks. Signatures, modules, and metrics give you the primitives for an LLM system that would otherwise be all over the place in terms of controllability.
Composability. Complex applications break down into smaller model calls and stitch back together as programs. You can iterate on individual components while still optimizing for system-level performance.
Data-driven optimization. Improvements come from data and metrics rather than manual prompt iteration. This matters most in production, where incremental gains and consistency compound.
Portability. Because behavior isn’t tightly coupled to handcrafted prompts, adapting to a new model or a slightly different use case becomes a re-optimization step rather than a rewrite. Technically, you’re a recompile away.
What to note with DSPy
Compile times can be at times significant, especially with LLM-as-judge metrics and huge datasets — every optimization involves tokens. Debugging in some cases may be harder than with raw prompts, because the thing you’re inspecting is generated rather than authored.
For one-off prototypes or small-scale tasks still hand-written prompts works fine. Where the framework earns its keep is when you have a system with multiple model calls, a metric, and data to optimize against.
The bigger shift
The most interesting thing about DSPy isn’t any single abstraction — it’s the bet underneath the framework. The bet is that prompt engineering, as a discipline, should look less like editorial work and more like software engineering: with interfaces, composition, tests, and a compile step.
None of this eliminates the need for good initial design or intuition. But it does reduce the reliance on chaotic ad-hoc iteration and brings LLM systems closer to the engineering practices the rest of our stack already takes for granted. For teams trying to scale LLM work, that shift may matter more than any individual optimizer.
Co-Founder & Head of AI